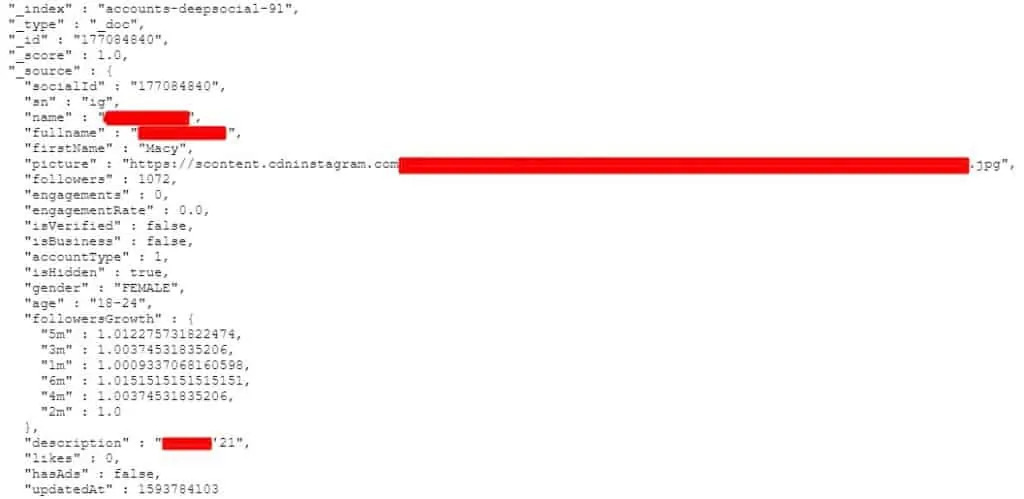
Web scraping is a technique of gathering data from web pages in an automated manner. While it’s not illegal, social media companies prohibit this practice to protect user data. However, a lot of analytics companies create large databases of user information by using web scrapers on popular sites. Some of these companies often sell insights from these databases to other firms. Bob Diachenko, the lead researcher for security firm Comparitech, found three identical copies of the database on August 1. According to Diachenko and the team, the data belonged to a now-defunct company called Deep Social. When they reached out to the company, the request was forwarded to Hong-Kong-based firm Social Data, who acknowledged the breach and closed the access to the database. However, Social Data denied having any links with Deep Social. [Read: Google admits its Android Auto assistant is a little, umm, slow] In a statement, the company’s spokesperson said that all the data collected was public, and it wasn’t collected suspiciously: However, firms such as YouTube, Instagram, and TikTok prohibit web scraping practices. We’ve asked these companies to provide a comment, and we’ll update the story if we hear back. The scraped data had four major datasets with details of millions of users from the aforementioned platforms. It contained information such as profile name, full name, profile photo, age, gender, and follower stats. This kind of data is often used for phishing and spam campaigns. So, it’s up to companies to keep their databases secure. Last year, Diachenko uncovered a database containing scraped information of 267 million Facebook users. Last October, a US court said that it’s not illegal to scrap data without a website’s permission. Did you know we have an online event about the future of work coming up? Join the Future of Work track at TNW2020 to hear how successful companies are adapting to a new way of working.